
目录 · Table of Contents
DATASET DESCRIPTION
The iNaturalist Challenge 2019 dataset (the iNat dataset) contains two folders and three json files(https://www.kaggle.com/c/inaturalist-2019-fgvc6/data):
- train_val2019 folder – Contains 268,243 training and validation images in a directory structure following {iconic category name}/ {category name}/ {image id}.jpg.
- test2019 folder – Contains a single directory of 35,350 test images.
- test2019.json – Contains test image information.
- train2019.json – Contains the training annotations.
- val2019.json – Contains the validation annotations.
The images contain six kinds of creatures: Fungi, Plants, Insects, Amphibians, Reptiles and Birds, which are then divided into more specific sub-classes. Some creatures, such as Plants, includes as many as 682 sub-classes while some creatures, such as Fungi, includes only 11 sub-classes. There are 1010 sub-classes in total. All images are provided in the JPEG format and resized to have a maximum dimension of 800 pixels.
The size of the dataset exceeds 82GB. Since the GPU of spartan server which is the only hardware support of this project has only 12GB memory, it is hardly to train the original dataset on this GPU. To read data efficiently, the TFRecords has been used to cache the data-preprocessing. With using the TFRecords, the original dataset has been reshaped and serialized to three kind of dimensions, 299*299, 512*512 and 800*800, and the size of the datasets are reduced to 5.2GB, 12.1GB, 25.7GB respectively.
EXISTING METHODS
In the field of computer vision, the main method to increase the accuracy of deep learning model is to make deeper and deeper neural networks in the past. However, it has several problems such as overfitting, superabundant parameters. In 2012 ImageNet classification challenge, AlexNet (Krizhevsky et al., 2012), which is the first entry that used a Deep Neural Network (DNN) (Canziani et al, 2017), made a breakthrough in this competition (Russakovsky et al., 2015). With the emergence of DNNs, the accuracy figures of the competitions like the ImageNet classification challenge have steadily increased.
Since the pre-trained models are allowed in the competition, finding a suitable training model is very crucial. Like the ImageNet classification challenge, the ultimate goal of the iNaturalist Challenge is to obtain the highest accuracy in a multi-class classification problem framework. Therefore, the DNNs is the potential solutions for the project.
Canziani et al. (2017) analysed multiple DNNs submitted to the ImageNet challenge in terms of accuracy, parameters and other indexes. The Figure 1 (Canziani et al, 2017), show the Top-1 accuracy of the ImageNet classification challenge versus network, amount of operations required for a single forward pass and parameters.
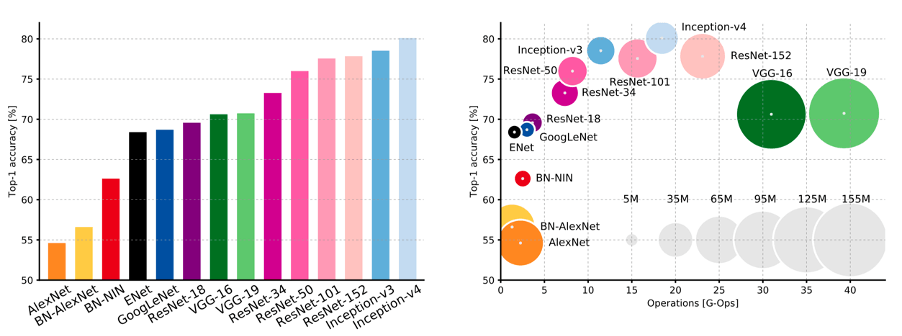
Apparently, the inception series models have the highest accuracy among any other models in the figure.
Inception series models
In 2014, GoogLeNet put forward a new concept to merge the convolution kernel by a “Bottleneck Layer” to solve the problem of overfitting and superabundant parameters, and this new model is Inception v1 (Ioffe & Szegedy, 2015).
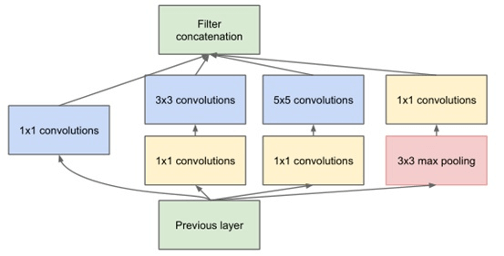
Inception v1 use structure shows as the Figure 2 and sequentially connect them together. However, this model is still easy to overfit and it also have too many parameters. In 2015, GoogleNet put forward Inception v2 and v3 models. In Inception v2 model (Szegedy et al., 2016), the alternative for one 5 × 5 kernel is to use two 3 × 3 size kernels to process the same image portion with less training parameters. Also, the batch normalization layers are added and n × n convolution is replaced by several 1 × n or n × 1 convolutions. Furthermore, comparing with the Inception v2, the Inception v3 model applies the convolution and pooling layer in parallel structure instead of putting them in sequence to reduce the dimension to diminish the target image size (Szegedy et al., 2016).
Szegedy et al. (2017) achieve 3.08% top-5 error on the test set of the ImageNet classification (CLS) challenge by using Inception v4 model. Inception v4 replaces the sequential connection of CNN layers and Pooling layers into stem module, in order to achieve deeper structure (Szegedy et al, 2017).
The Inception ResNet series model (Szegedy et al., 2017) came from the Inception series model by adding the ResNet residual structure. It has two versions, Inception ResNet v1 and Inception ResNet v2, which were derived from Inception v3 and Inception v4 respectively. Compared with the original Inception model, the Inception ResNet model added the shortcut structure and applied the linear 1×1 kernel to align the dimension.
POTENTIAL SOLUTION AND HYPOTHESIS
Our potential solution is using the Inception ResNet v2 which is a hybrid Inception version that has best performance currently and a similar computational cost to Inception-v4. Since the Spartan provides limited source, we chose the Inception v3 model (Szegedy et al., 2016) as the second choice, which is much cheaper than Inception-v4 in computational cost.
| Model | Inception v3 | Inception ResNet v2 |
| Total Parameters | 21,802,784 | 54,336,736 |
| Trainable Parameters | 21,768,352 | 54,276,192 |
| Non-trainable Parameters | 34.432 | 60,544 |
Our hypothesis is without changing the model structure, the accuracy is related to the following hyperparameters and methods: Learning rate, Optimizers, Batch size and buffer size, and images resolution.
The learning rate is the most important parameters that affect the accuracy, the significant impact has been found during testing.
For optimizers, currently, we use the RMSprop, Adam and Nadam as our optimizers.
About the batch size, although that small batch size may create noise that can prevent overfitting, but as far as we tested, big batch show higher performance than small batch size, however, when the batch size exceeds a certain value, it will no longer have big impact on the accuracy. Buffer size do not have big impact on the accuracy. But large buffer size can help to select images more randomly to form a batch.
PROCESS OF TUNING THE PARAMETERS
The table in appendix shows the part of training loss/accuracy and validation loss/accuracy corresponding with the different parameters set up in the two pretrained models.
From the table in appendix, we can see the details of our training attempts. It includes model types, parameters (Resolution, Epochs, Batch sizes and learning rate) and the loss and accuracy we finally got at validate set.
Because of the limitation of the Spartan GPU memory, trying 512*512 resolution requires us to reduce the batch size to very small, and failed to achieve an ideal result. We have also tried the 800*800 resolution, but never succeeded. Therefore, we turned to focus on tuning the parameters to train the 299*299 datasets.
For the same reason above, the highest batch size of inception-v3 which can be afford by Spartan GPU memory is 72, when we were training the 299*299 datasets with learning rate 0.0001 and the RMSprop as optimizer (it may change according to the learning rate and optimizer), while for the ResNet v2, it is 40.
During the process of tuning parameter, it can be found that in the same condition, the bigger the batch size, the higher the accuracy of the test. According to this, we set the maximum batch size we can allocate and then change the optimizer and learning rate. We attempted three optimizers, RMSprop, Adam, which is essentially RMSprop with momentum, and Nadam which is Adam RMSprop with Nesterov momentum, and tuned the learning rates from 0.01 to 0.00001.
RESULTS AND CONCLUSIONS
The current best of the whole training process is shown as the Table 2:
| Pre-trained Model | Inception ResNet v2 |
| Pooling | global_average_pooling2d |
| Dropout | 0.5 |
| Dense | linear |
| Batch size | 36(train), 128(validation) |
| Buffer size | 500(train), 500(validation) |
| Target size | 299*299 |
| Optimizer | Nadam |
| Learning Rate | 0.0001 |
| Total epoch | 30 |
| Best epoch | 25/30 |
| Train loss/acc | 2.0379/0.7271 |
| Validation loss/acc | 1.5260/0.6398 |
| Test score/acc | 0.3628/0.6372 |
The full output text of current best can be check in appendix. For some reasons, we failed to submit the current best result to Kaggle before the deadline of the competition. But finally, we fixed the problem and submitted with our current best.


From all the attempts, three conclusions can be made: firstly, the Inception ResNet v2 has better performance than Inception v3 in the same condition excluding the computational cost; secondly, big batch show higher performance than small batch size within reasonable limits; thirdly, it can be found the improvement of Nadam over Adam and RMSprop.
REFERENCE
Christian, S., Sergey, I., (2017). Inception V4, Inception ResNet and the Impact of Residual Connections on Learning. The Thirty-First AAAI Conference on Artificial Intelligence.
Howard, A., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M. & Adam, H., (2017). MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
iNaturalist 2019 at FGVC6 (2019, May). Retrieved from (https://www.kaggle.com/c/inaturalist-2019-fgvc6/data).
Inat2019 Starter Keras (2019, May). Retrieved from (https://www.kaggle.com/ateplyuk/inat2019-starter-keras/notebook).
Ioffe, S., & Szegedy, C. (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, 448–456.
Keras MobileNet Data Augmentation & Visualize (2019, May). Retrieved from (https://www.kaggle.com/hsinwenchang/keras-mobilenet-data-augmentation-visualize/comments).
Szegedy, C., Ioffe, S., & Vanhoucke V., (2016). Inception-v4, inception-resnet and the impact of residual connections on learning. In ICLR Workshop.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A., (2015). Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1–9.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z., (2015). Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567.